
Tokenization is the process of breaking a stream of textual data into characters, subwords, words, terms, sentences, symbols, or some other meaningful elements called tokens.
Tokenization is the first step in any NLP task and has an important effect on rest of our pipeline for the task. A tokenizer breaks raw text into tokens, which can be used directly as a vector representing that document.
In this project, we experiment with Byte-Pair Encoding ( BPE ) - a subword-based tokenization scheme. BPE was originally developed for data compression and later adapted for tokenization in NLP. The core idea behind BPE is to iteratively merge the most frequent pairs of bytes (or characters in the context of NLP) into a single, new byte (or token).
With this basic set of information, let's get into what this project is all about.
Motivation
BPE tokenization merges characters into longer tokens by finding frequently occurring contiguous patterns, such as -ing or -ly within the word boundary. This project stretches the motivation further by allowing BPE to cross word boundaries.
Multiword Expressions ( MWEs ) are expressions which are made up of at least 2 words and which can be syntactically and/or semantically idiosyncratic in nature. Moreover, they act as a single unit at some level of linguistic analysis.
N-gram tokens have been used in traditional NLP for a long time and with much success. For example, "New York", a bigram ( a token consisting of 2 words ) can be a concise yet useful feature in a Named Entity Recognition task. Similarly, a Spanish-Neglish Machine Translation ( MT ) model might benefit from having the bigram te amo or its trigram translation I love you in its vocabulary. Finally, a model’s vocabulary could even extend to non-contiguous tokens or k-skip-n-grams such as neither · nor. This token reappears in several contexts e.g. neither tea nor coffee and neither here nor there ( underlined words replace the · skip).
Extending BPE
In this project, we experimented with two kinds of ways to add MWEs to a BPE vocabulary.
-
BPE beyond words : In this approach, we used BPE+ngms ( ngms - N-grams ) i.e. allowing BPE to choose between not just adding subwords but also frequently occurring n-grams. For this prject, we limited to use bigrams and trigrams. Besides continuous MWEs we also experimented with discontinuous MWEs, i.e., k-skip-n-grams, which we refer to concisely as skipgrams. In particularly, we focus on 1-skip-3-grams e.g., neither · nor, I · you .
-
Adding MWEs with PMI : However, the above approach does not work well in practice. Therefore, instead of raw frequency, here we find MWEs using a common technique of finding word collocations: Pointwise Mutual Information (PMI), which is a measure of the association between two word types in text. We used similar MWEs ( bigram, trigrams, combination of bigram and trigrams, and skipgrams )

In the interest of keeping this article concise, I will not dive deep into all the parameters used for finding MWEs, the dataset and experiment configurations used for Neural Machine Translation (NMT) experiments.
Results and Discussions
Empirically we observe that BPE with high frequency MWE tokens see a drop in performance whereas the PMI counterpart as well as the original baseline (within word boundary) performs well. What then happens at the word boundary that the BPE algorithm stops working? We hypothesize that this is the result of words combining in more diverse ways than subwords.
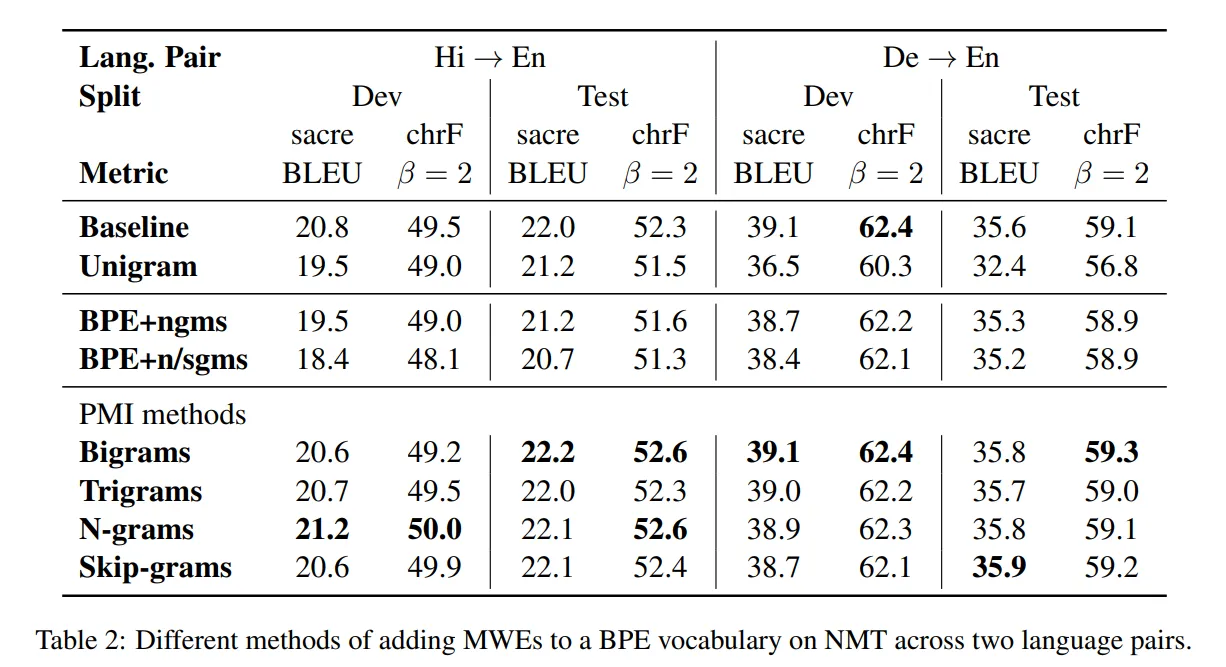
High frequency MWE tokens include n-grams like in_the, that_in, of_the, etc. However, as seen in the table adding these tokens hurts the performance. Words like in, the, of, etc. make many versatile combinations, which is rarely observed at the subword level. Suffixes like -ing almost never appear as prefixes whereas prefixes like de almost never appear as suffixes. When such subwords combine to form longer tokens, they generally retain a coherent meaning, unlike n-grams like in_the.
Finally, this hypothesis may explain why MWEs ordered by PMI help improve MT scores – they are by definition units that co-occur as a coherent unit. Indeed, the MWEs thus found (e.g. New_York, per_cent) include constituents which exclusively form only these tokens.
I would really like to thank Avijit Thawani, who brought up this idea and project to life and was the major driving force behind these experiments.