
Introduction
In this project, we aimed to address the problem of chunking for Hindi language using a pre-compiled library of Conditional Random Fields (CRF) with Viterbi Decoding. The objectives of the projects included: exploring the pre-compiled library for Hindi chunking, perform error analysis at word/POS/sentence-level and identify common patterns in erroneous predictions.
Some Prerequisite Knowledge
Chunking or shallow parsing is a process of meaningful extraction of short phrases from the sentence.
Chunks are made up of words and kind of words are defined by the POS (Part of Speech) tag of the words. There is a standard set of POS-tags like: noun (N), verb (V), adjective (ADJ), etc. For example, the sentence : The little yellow dog barked at the cat
The/DT little/JJ yellow/JJ dog/NN barked/VBN at/IN the/DT cat/NN ./.
Chunking works on top of POS tagging, it uses POS-tags as input and provides chunks as output. Similar to POS tags, there are a standard set of chunk tags like Noun Phrase(NP), Verb Phrase (VP), etc. For example, the sentence : He reckons the current account deficit will narrow to only # 1.8 billion in September, can be chunked as shown:
[NP He ] [VP reckons ] [NP the current account deficit ] [VP will narrow ] [PP to] [NP only # 1.8 billion ] [PP in [NP September ]].
Conditional Random Fields (CRF) are a discriminative model, used for predicting sequences. They use contextual information from previous labels, thus increasing the amount of information the model has to make a good prediction.
Viterbi decoding is a dynamic programming approach that is used for the maximum likely-hood decoding of a sequence of states.
What did we do ?

First of all, before going further, we pre-processed the Hindi TreeBank data from SSF ( Shakti Standard Format ) to a list of dictionaries, each dictionary represented a word and included word and chunk category and morph features like number, gender, case, root word, etc. Moreover, we divided chunk category in two parts: B- marking the beginning of the chunk and I- marking the internal of the chunk.
We used the sklearn-crfsuite library for training and predicting the results. We used L-BFGS optimization algorithm for parameter estimation.

We used different modes, where each mode represented a combination of different morph features and calculated F1-scores for them. Once, the models were trained, we did different kinds of error analysis.
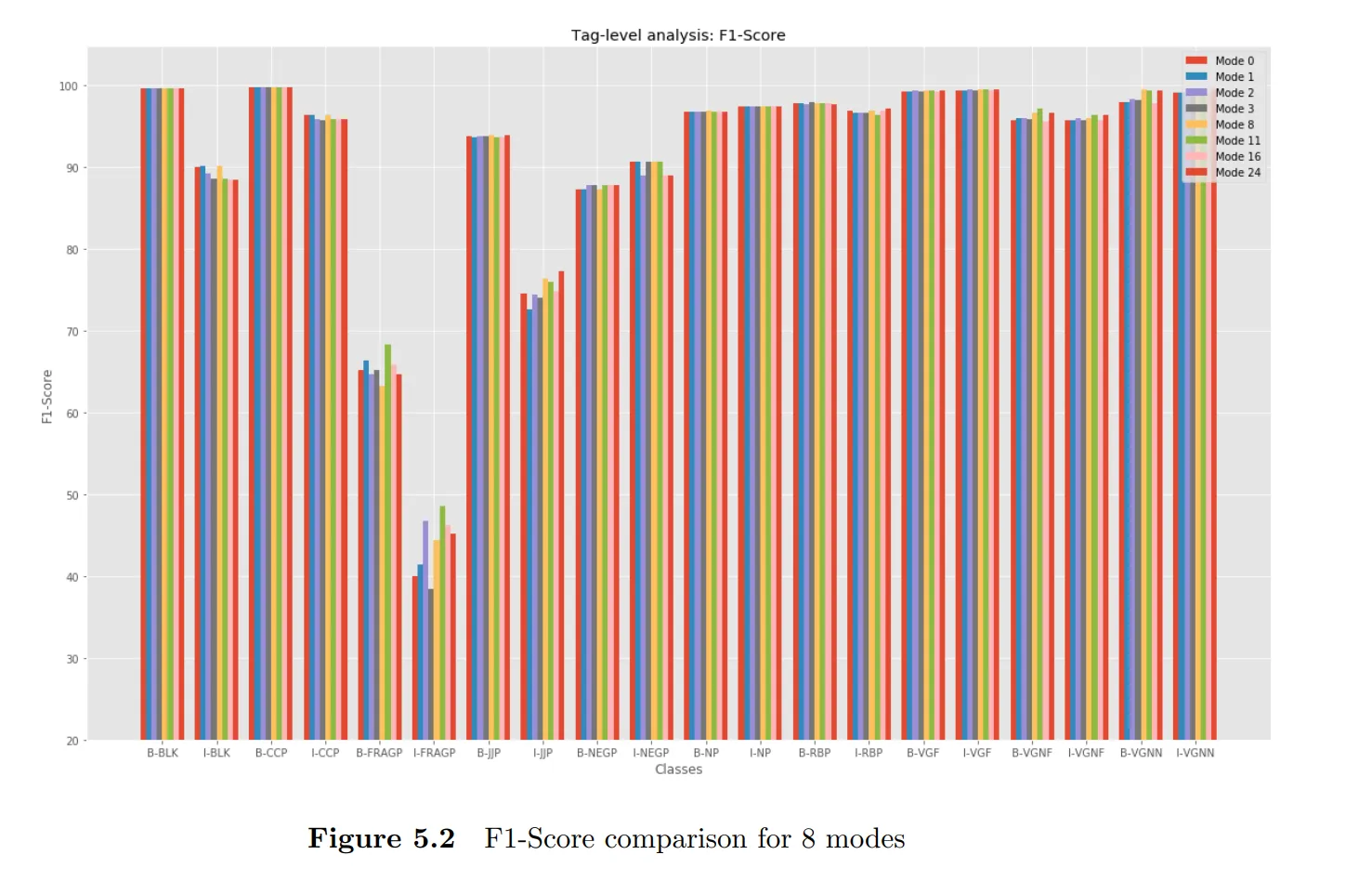
Tag Level Analysis : We calculated F1-scores, precision and recall for the prediction of different chunk tags. From the graph below, we observed that the performance of FRAGP and NEGP tags are very staggering. We believe that the main reason for this error is that the probability of predicting a sequence to be NP or NP+FRAGP becomes quite similar in many cases and thus, it becomes hard to get the correct chunk tag.
Similarly is the case with NEGP, which in general combines with verb groups to form VGNF however due to presence of NP in between it is not possible and is often grouped with others.
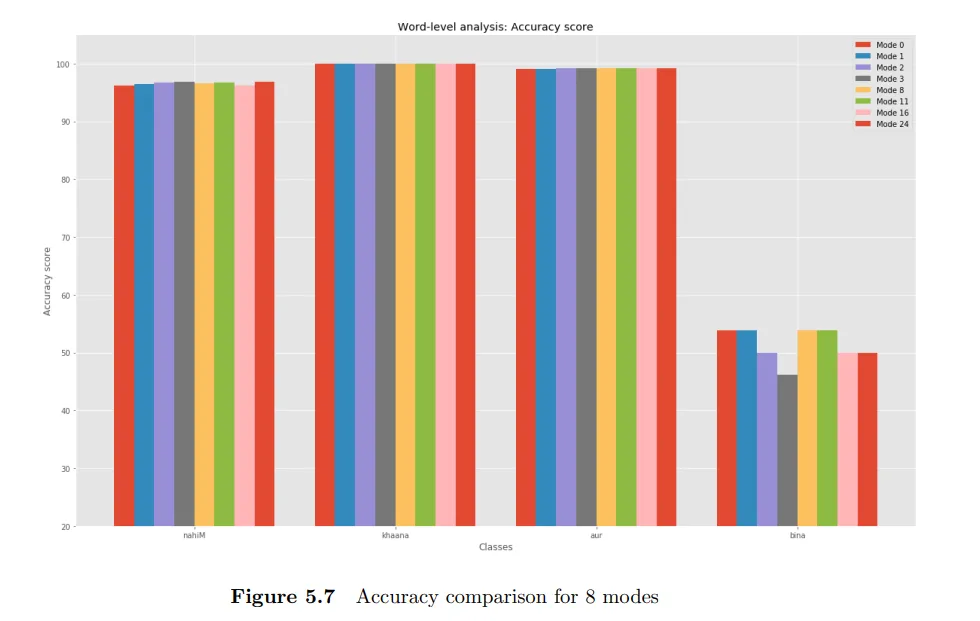
Word Level Analysis : Here we focused on various words to understand how the model behaves for them. Let's consider an example to understand better.
बिना कुछ बोले काम नहीं चलता ( witout speaking something work does not go on )
Here, the noun कुछ comes between the negative बिना and verb बोले. Here, it is not possible to group the negative and the verb as one chunk. At the same time, बिना cannot be grouped within an NP chunk as functionally, it is negating the verb and not the noun. To handle such cases an additional NEGP chunk is introduced. If a negative occurs away from the verb chunk, the negative will be chunked by itself and chunk will be tagged as NEGP.
However, our model treated बिना कुछ as an NP chunk, because it couldn’t train itself on any provided feature which could determine this NEGP case.
Another example of ambiguity is the word खाना, which appears in both NP ( as it means food ) and VP ( as it also means the act of eating ). However, the model worked very well on this word.
Sentence Level Analysis : Sentence level analysis is done on two measures: correct sequence of chunk tag prediction and correct boundary prediction of the chunk. We plot heat-maps for different modes, where each heat map depicts the accuracy of the prediction of the tag sequences. One common trend we saw was that, as we included more morph features, the accuracy for various tags improved.
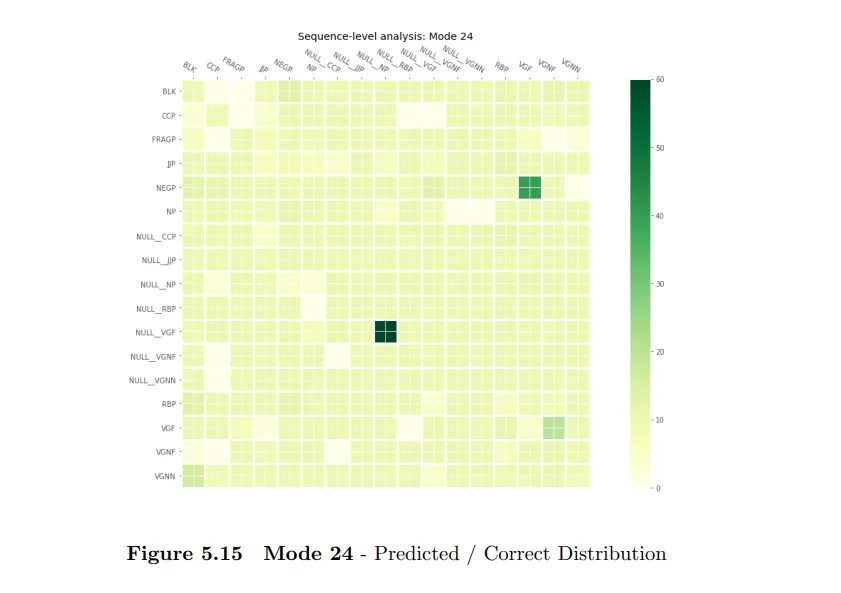
Next, we analyzed the prediction of correct chunk boundaries and observed that NP and JJP are the tags where the boundaries are skipped the most. For example, suppose a sentence consists of following chunks NP NP NP VP, however our model predicts the sequence as NP NP VP i.e boundaries are skipped.
One interestng thing to note here is that, NP is also the chunk where more boundary prediction happens in other cases. Apart from NP, NULL_VGF is a case where extra boundaries appear. This error stems from the fact that the model predicts a verb group as a combination of a verb group and NULL_VGF.
Conclusions
After doing error analysis on various levels we come to the conclusion that, there occurs pattern in the dataset which are more prone to error, and certain feature sets perform distinctly better than the others.
- Predicting NP as NP + FRAGP and vice-versa is a very common error that occurs. Apart from that, prediction of NEGP tag is also error prone.
- Use of ‘case’ in the feature set shows better results in prediction of the results. Suffixes can also play a role in predicting the values correctly.
- Some words like बिना ( without ) are not predicted that well by the model.
- At many places, NP and JJP boundaries are both skipped and created(extra). Although overall sequence order is maintained but such errors occur much more frequently.
References
- An Introduction to Conditional Random Fields
- Himanshu Agrawal, 2016, Part of Speech Tagging and Chunking with Conditional Random Fields, IIIT Hyderabad
- sklearn-crfsuite
- SSF: Shakti Standard Format Guide